| Problem
| Problemlösung
|
|
| Zeichensatz nicht angeben
|
- Ohne Angabe des Zeichensatzes stellen manche Programme (z. B. Editor unter Windows oder Microsoft Excel) Zeichensalat dar.
| Zeichensatz angeben
|
|
| nur die ersten 65 536 Unicode-Zeichen verwenden
- Unicode umfasst heute mehr als 100 000 Schriftzeichen. Die gängigsten Schriftdateiformate (TrueType und OpenType) können jedoch maximal 65 536 Zeichen enthalten.
| mehrere verschiedene Schriftarten verwenden
|
|
|
- exakt nach Spezifikation programmieren
- ungültige Codes nicht korrigieren und nicht löschen
|
|
|
- als Autor:
- Unicodezeichen möglichst vermeiden
- von mehreren Varianten die älteste bevorzugen (Das ist einer der Gründe, wieso ich ASCII-Anführungszeichen verwende, obwohl Sprachliebhaber diese für "grauenhaft falsch" halten.)
- als Programmierer: ähnliche Zeichen, die für Verwechslungen sorgen könnten, ausschließen
- als Leser: Texte in einem 8-bit-Zeichensatz (für Westeuropa: ISO-8859-1) abspeichern. Unnötige Unicode-Zeichen werden dabei sichtbar und können entfernt bzw. ersetzt werden.
- Für vorgetäuschte Internetadressen wurde noch keine gute Lösung gefunden. (Ich wäre dafür, auf Nicht-ASCII-Zeichen zu verzichten.)
|
|
| in Internet-Adressen nur ASCII-Zeichen verwenden
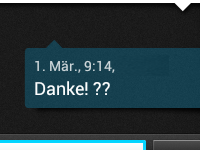
- Wenn ein Unicode-Zeichen nicht darstellbar ist, wird stattdessen ein Fragezeichen oder gar nichts angezeigt. Es kann kein Alternativtext definiert werden (wie z. B. in HTML für Bilder).
|
|
- Unicode-Zeichen Nr. 55 296–57 343 gibt es nicht. Diese Zahlen sind für die Codierungsvariante UTF-16 reserviert. Bei der Umwandlung in UTF-8 werden oft fälschlicherweise diese Zahlen anstatt die durch sie angegebene Unicode-Zeichennummer verwendet. (Alte Software hat eine Entschuldigung, da der Spezialfall für die Zeichennummern 55 296–57 343 erst 1996 eingeführt wurde, um mehr als 65 536 Zeichen darstellen zu können.)
| Diese Fehlfunktion wurde nachträglich als CESU-8 standardisiert. Bei jeder Software ist zu testen, ob sie diesem Standard folgt oder korrektes UTF-8 produziert.
|
|
|
- Unicode-Zeichen vermeiden
- Mail oder Chat-App (wie z. B. WhatsApp) verwenden
|
|
|
- Worte benutzen
- Grafiken anstatt Unicode-Zeichen benutzen
|
|
| FTP-Server auf UTF-8 umstellen; keine alten Zugangsprogramme mehr verwenden
|
| | | |